
DataLearner es una herramienta fácil de usar para la minería de datos y el descubrimiento de conocimientos a partir de sus propios conjuntos de datos de entrenamiento compatibles con el formato ARFF y CSV (* ver más abajo). Es totalmente autónomo, no requiere almacenamiento externo ni conectividad a la red y construye modelos directamente en su teléfono o tableta. Esto no es un curso de formación o un libro – es una genuina aplicación de minería de datos basada en el aprendizaje de máquinas.
Soporte ARFF y CSV
Los conjuntos de datos de entrenamiento deben ajustarse al formato Weka ARFF o CSV (variable separada por comas). Los archivos CSV deben tener las siguientes características:
* deben incluir una fila de cabecera
* el atributo de clase se establece inicialmente como última columna
Forzar el atributo de clase a nominal
La mayoría de los algoritmos de DataLearner esperan atributos de clase nominales/categóricos y el uso de un atributo de clase numérico hará que la mayoría de los algoritmos fallen. La nueva opción forzar atributo de clase a nominal supera esto, sin embargo, los atributos de clase nominales con demasiados valores distintos pueden utilizar demasiada memoria RAM.
*** ¡NOVEDADES! La investigación de DataLearner ha sido seleccionada para su presentación en ADMA 2019 (15th International Conference on Advanced Data Mining and Applications) y se publicará en Lecture Notes in Artificial Intelligence (Springer) ***
DataLearner presenta algoritmos de clasificación, asociación y agrupación del paquete de código abierto Weka (Waikato Environment for Knowledge Analysis), además de nuevos algoritmos desarrollados por la Unidad de Investigación de Ciencias de los Datos (DSRU) de la Universidad Charles Sturt. En conjunto, la aplicación proporciona 42 algoritmos de aprendizaje automático/minado de datos, incluyendo RandomForest, C4.5 (J48) y NaiveBayes.
DataLearner no recoge ninguna información y requiere acceso al almacenamiento de su dispositivo simplemente para cargar sus conjuntos de datos y construir sus modelos de aprendizaje automático.
DataLearner se está utilizando como herramienta docente en la asignatura ITC573 Ingeniería de Datos y del Conocimiento del posgrado Master of Information Technology de la Universidad Charles Sturt.
Obtenga los recursos:
Código fuente con licencia GPL3 en Github: https://github.com/darrenyatesau/DataLearner
Vídeo rápido en YouTube: https://youtu.be/H-7pETJZf-g
Papel de investigación en arXiv: https://arxiv.org/abs/1906.03773
Papel de la conferencia AusDM 2018 que dio inicio a DataLearner: https://www.researchgate.net/publication/331126867
Investigadores, si utilizan esta app en aplicaciones de investigación, por favor, citen los papeles de investigación anteriores. Gracias.
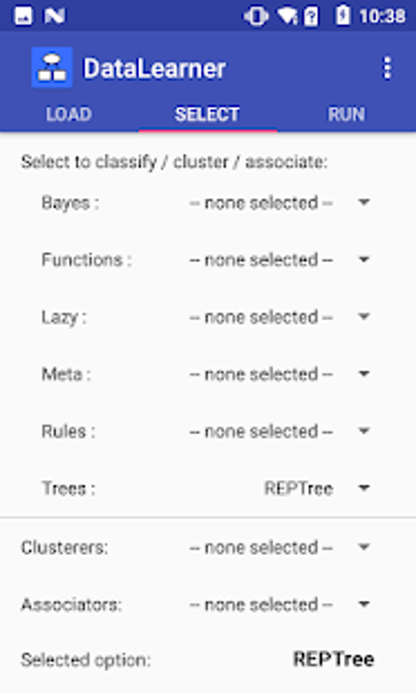
Los algoritmos de aprendizaje automático incluyen:
Bayes BayesNet, NaiveBayes
Funciones Logistic, SimpleLogistic, MultiLayerPerceptron (Red Neural)
Lazy IBk (K Nearest Neighbours), KStar
Meta AdaBoostM1, Bagging, LogitBoost, MultiBoostAB, Random Committee, RandomSubSpace, RotationForest
Reglas Regla Conjuntiva, Tabla de Decisión, DTNB, JRip, OneR, PART, Ridor, ZeroR
Árboles ADTree, BFTree, DecisionStump, ForestPA, J48 (C4. 5), LADTree, Random Forest, RandomTree, REPTree, SimpleCART, SPAARC, SysFor.
Clusterers DBSCAN, Expectation Maximisation (EM), Farthest-First, FilteredClusterer, SimpleKMeans
Asociaciones Apriori, FilteredAssociator, FPGrowth
>> ¿Dónde encontrar archivos de conjuntos de datos?
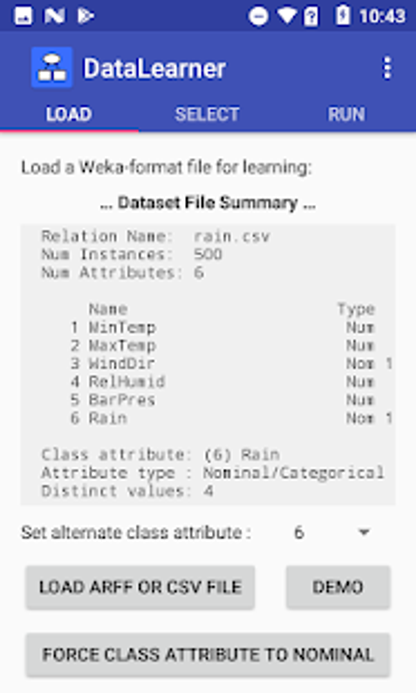
DataLearner viene con un conjunto de datos de demostración incorporado llamado rain.csv, pero también encontrará muchos conjuntos de datos en el sitio web de OpenML – incluyendo el popular conjunto ecoli (https://www.openml.org). Descarga las versiones ARFF en tu teléfono y cárgalas en DataLearner para construir modelos a partir de ellas. Vea nuestro nuevo video tutorial – https://www.youtube.com/watch?v=81tSbclMVT8
Este software se suministra TAL CUAL – aunque ha sido probado, no se ofrece ninguna garantía.