



El mercado de la ciencia de los datos, el aprendizaje automático y la inteligencia artificial está en auge.
La ciencia de los datos consiste básicamente en convertir los datos estructurados o no estructurados en información, comprensión y conocimiento utilizando métodos, procesos y algoritmos científicos.
R y Python son los lenguajes de programación más comunes utilizados en la ciencia de los datos.
R es un lenguaje de código abierto gratuito utilizado como software estadístico y de visualización. Puede tratar con datos estructurados (organizados) y semiestructurados (semi-organizados).
Para aprender R para la ciencia de datos cubrimos todos los aspectos de la siguiente manera:
Introducción
Datos. Tipos en R
Variables en R
Operadores en R
Estados condicionales
Estados de bucle
Estados de control de bucle
Script en R
Funciones en R
Función personalizada
Estructuras de datos
Vectores atómicos vectores
Matriz
Arrays
Factores
Marcos de datos
Lista
Asignación de valores a la estructura de datos
Manipulación/Transformación de datos
Aplicación de la función de R base
Paquete dplyr
Para Python cubrimos lo siguiente –
Configuración del entorno y fundamentos de Python
Introducción y configuración del entorno
Asignación de variables en Python
Tipos de datos en Python
Estructura de datos: Tuple
Estructura de datos: Lista
Estructura de datos: Diccionario (Dict)
Estructura de datos: Conjunto
Operador básico: in
Operador básico: + (plus)
Operador básico: * (multiplicar)
Funciones
Función de secuencia incorporada en Python
Estados de flujo de control: if, elif, else
Estados de flujo de control: bucles for
Estados de flujo de control: bucles while
Manejo de excepciones
Cálculo matemático con NumPy en Python
Tipos de Arrays
Atributos de ndarray
Operaciones básicas
Acceso a Array Elementos
Copia y Vistas
Funciones Universales (ufunc)
Manipulación de Formas
Difusión
Álgebra Lineal
Manipulación de Datos con Pandas
¿Por qué Pandas?
Estructuras de Datos
Creación de Series
Elementos de Acceso a Series
Operaciones de Vectorización de Series
Creación de DataFrame
Visualización de DataFrame
Manejo de Valores perdidos
Operaciones de datos con funciones
Funciones estadísticas para operaciones de datos
Operaciones de datos con GroupBy
Operaciones de datos: Ordenación
Operación de datos: Merge, Duplicate, Concatenation
Operaciones SQL en Pandas
La estadística es una parte crucial para empezar a aprender en este campo.
Los términos utilizados en estadística son muy extraños y difíciles de entender para los principiantes, así que nos esforzamos por explicar estos términos en un lenguaje muy fácil para los chicos de nivel novato, intermedio o avanzado en el campo de la Ciencia de Datos, el Aprendizaje Automático y la IA.
Aquí cubrimos tantos términos utilizados en la estadística como.
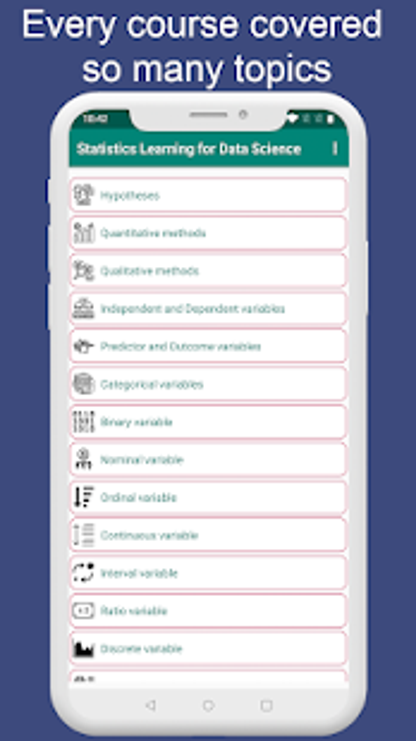
Hipótesis
Métodos cuantitativos
Métodos cualitativos
Variables independientes y dependientes
Variables predictoras y de resultado
Variables categóricas
Variable binaria
Variable nominal nominal
Variable ordinal
Variable continua
Variable de intervalo
Variable de razón
Variable discreta
Variables de confusión
Error de medición
Validez y fiabilidad
Dos métodos de recogida de datos
Tipos de variación
Variación no sistemática
Variación sistemática
Distribución de frecuencias
Media
Modo
Dispersión en la distribución de Datos
Rango
Rango intercuartil
Cuartiles
Probabilidad
Desviación estándar
La ventaja más importante de esta aplicación es que el material completo, excepto el proyecto de muestra, está disponible sin conexión, la parte del proyecto de muestra está en línea porque seguimos añadiendo regularmente en la web.
Compilador en línea en el dispositivo móvil, puede escribir el código en el móvil y ejecutarlo para ver la salida.
Prueba de simulación/examen – Compruebe sus conocimientos en Ciencia de Datos intentando este examen de simulación, cada pregunta tiene 4 opciones y 1 respuesta correcta.